Table of Contents

INTRODUCTION
While working on a high-traffic SaaS platform in the customer engagement space, our engineering team encountered a situation where automated deployments suddenly ground to a halt. The system relied on a robust CI/CD pipeline integrated with cloud-native deployment controllers and Auto Scaling Groups (ASGs) to manage application fleet capacity across various regions.
During a critical release window, new instances failed to provision, effectively breaking our rolling deployment strategy. As we dug into the logs, we realized the deployment failure wasn’t caused by a configuration error, a bad AMI, or a networking issue, but rather an infrastructure capacity ceiling we hadn’t been warned about. Even more puzzling was that our subsequent request to increase this capacity was completely stalled.
This incident highlighted a crucial blind spot where cloud infrastructure operations intersect with account governance. It inspired this article to help other engineering leaders avoid the same mistake. When system availability is on the line, assuming that infrastructure limits are purely technical can lead to extended downtime. This is why many organizations prefer to hire software developer teams that understand both the architectural and operational realities of enterprise cloud environments.
PROBLEM CONTEXT
The SaaS application architecture utilized an automated deployment group that rotated underlying compute resources during releases. Under normal conditions, the Auto Scaling Group would spin up new instances, register them with the load balancer, wait for health checks to pass, and gracefully terminate the older fleet.
Because the platform was experiencing rapid user growth, the underlying compute utilization had organically scaled from a modest footprint to a much larger fleet over several months. The infrastructure was designed to scale dynamically based on CPU utilization and memory pressure, ensuring high availability during peak traffic spikes.
However, the automated pipeline completely failed when attempting to scale out during the latest deployment. The ASG could not fulfill the desired capacity, leaving the deployment in a suspended, degraded state. When engineering scaling mechanisms fail silently, it jeopardizes release velocity and system reliability.
WHAT WENT WRONG
Our initial diagnostic steps led us straight to the orchestration logs. The deployment controller reported that the ASG was unable to launch new instances. Checking the ASG activity history revealed a clear but unexpected error: VcpuLimitExceeded.
Upon reviewing the cloud provider’s Service Quotas dashboard, we found an alarming discrepancy. The account had a hard limit of 8 vCPUs for Standard on-demand instances in that specific region, yet the production environment was actively utilizing over 60 vCPUs. This mismatch often occurs when legacy grandfathered limits are eventually enforced, or when different instance families (like Spot vs. On-Demand) share complex quota rules under the hood.
We immediately submitted a Service Quota increase request to bump the limit to a safe threshold of 80 vCPUs. Typically, these requests are handled by automated heuristics within minutes. But days passed, and the request remained in a pending state with zero communication from cloud support.
As we escalated the issue, a deeper, non-technical blocker emerged. We discovered that the cloud account had a significant past-due payment. Cloud providers employ automated risk and billing systems; if an account is in arrears, automated quota increases are immediately blocked, and manual reviews are suspended until the financial standing is resolved. The technical failure was a symptom of a FinOps breakdown.
HOW WE APPROACHED THE SOLUTION
Solving this required a dual-track approach: resolving the immediate governance blocker and re-architecting our monitoring to prevent future occurrences.
First, we had to bridge the gap between DevOps and the finance department. Engineering teams often operate with limited visibility into account billing health, but as this incident proved, billing anomalies are critical availability risks. We expedited the payment clearance with the finance team and notified cloud support, which immediately unlocked the quota increase workflow.
Second, we evaluated our observability posture. Why were we allowed to hit 60+ vCPUs on an 8 vCPU limit without a single warning? We determined that relying on the cloud provider’s default alerting was insufficient. We needed proactive, automated monitoring for all Service Quotas. This is exactly why technical leaders choose to hire cloud architects for scalable infrastructure—to anticipate and mitigate these hidden boundaries before they impact production.
FINAL IMPLEMENTATION
To ensure this issue never reoccurred, we implemented an automated Service Quota monitoring stack using cloud-native monitoring and alarming tools.
We configured custom metrics that tracked our actual vCPU usage against our applied quotas. When utilization reached 75% of the allocated limit, an alarm would trigger a high-priority alert to the platform engineering team’s communication channels.
Here is an example of the infrastructure-as-code structure we used to deploy these alarms dynamically:
{
"Type": "AWS::CloudWatch::Alarm",
"Properties": {
"AlarmName": "High-vCPU-Utilization-Warning",
"AlarmDescription": "Alerts when vCPU usage exceeds 75% of the Service Quota.",
"Namespace": "AWS/Usage",
"MetricName": "ResourceCount",
"Dimensions": [
{
"Name": "Service",
"Value": "EC2"
},
{
"Name": "Resource",
"Value": "vCPU"
},
{
"Name": "Type",
"Value": "Resource"
},
{
"Name": "Class",
"Value": "Standard/OnDemand"
}
],
"Statistic": "Maximum",
"Period": 300,
"EvaluationPeriods": 1,
"Threshold": 75,
"ComparisonOperator": "GreaterThanOrEqualToThreshold",
"TreatMissingData": "notBreaching",
"AlarmActions": [
"arn:aws:sns:region:account-id:engineering-alerts-topic"
]
}
}
Additionally, we integrated a weekly FinOps summary report into the engineering management dashboard, ensuring that account health metrics (including billing anomalies) were visible to technical leads.
LESSONS FOR ENGINEERING TEAMS
- FinOps is a core DevOps pillar: Your cloud architecture is only as reliable as your account standing. Past-due invoices will silently break automated scaling and block quota requests.
- Do not trust legacy limits: Cloud providers continually update how they calculate and enforce quotas. An account might temporarily bypass a limit due to deprecated logic, only to hit a hard wall during a crucial deployment.
- Proactive quota monitoring is non-negotiable: Build dashboards and alarms that track utilization against hard limits. Alert at 70-80% capacity to give teams time to process quota increase requests.
- Understand instance family quotas: vCPU limits are segmented by instance types (e.g., Standard, Spot, specific series). Ensure your ASG configurations align with the quotas you are actively monitoring.
- Bridge departmental silos: Ensure that infrastructure alerts and billing alerts share a communication channel. When organizations hire devops engineers for cloud automation, they must empower them with holistic account visibility.
WRAP UP
What initially appeared to be a complex Auto Scaling failure turned out to be a rigid intersection of cloud quotas and account billing policies. By identifying the root cause, resolving the financial blocker, and implementing proactive monitoring alarms, we restored deployment reliability and fortified the platform against future silent failures.
Building resilient, highly available cloud systems requires engineering maturity that looks beyond the code. If your organization is struggling with unpredictable infrastructure bottlenecks and needs dedicated technical expertise, contact us. Our vetted remote teams bring the operational experience necessary to keep your enterprise environments scaling smoothly.
Social Hashtags
#AWS #DevOps #FinOps #CloudComputing #SaaS #AWSQuota #EC2 #AutoScaling #CloudInfrastructure #PlatformEngineering
Frequently Asked Questions
ASGs will fail to launch instances if they encounter an infrastructure hard limit, such as a vCPU Service Quota. If proactive monitoring isn't configured, these failures happen silently at the exact moment the system attempts to scale out.
Yes. Cloud providers use automated risk management systems. If an account has an outstanding balance, automated workflows for infrastructure expansions—including Service Quota increase requests—are suspended until the account is back in good standing.
This typically happens when instance types are mixed (e.g., utilizing Spot instances, which have separate quotas) or if there was a delay in how the cloud provider enforced legacy default limits on older accounts.
Under normal circumstances with a healthy account history, automated quota increases are approved within minutes. However, if the request is large or the account has billing flags, it requires manual review, which can take days.
Implementing native cloud alarms (like CloudWatch integration with Service Quotas) is the most effective strategy. Alerting engineering teams when usage hits 75% ensures ample time to request increases before production is impacted. Many enterprises hire aws developers for enterprise modernization specifically to implement these robust observability practices.
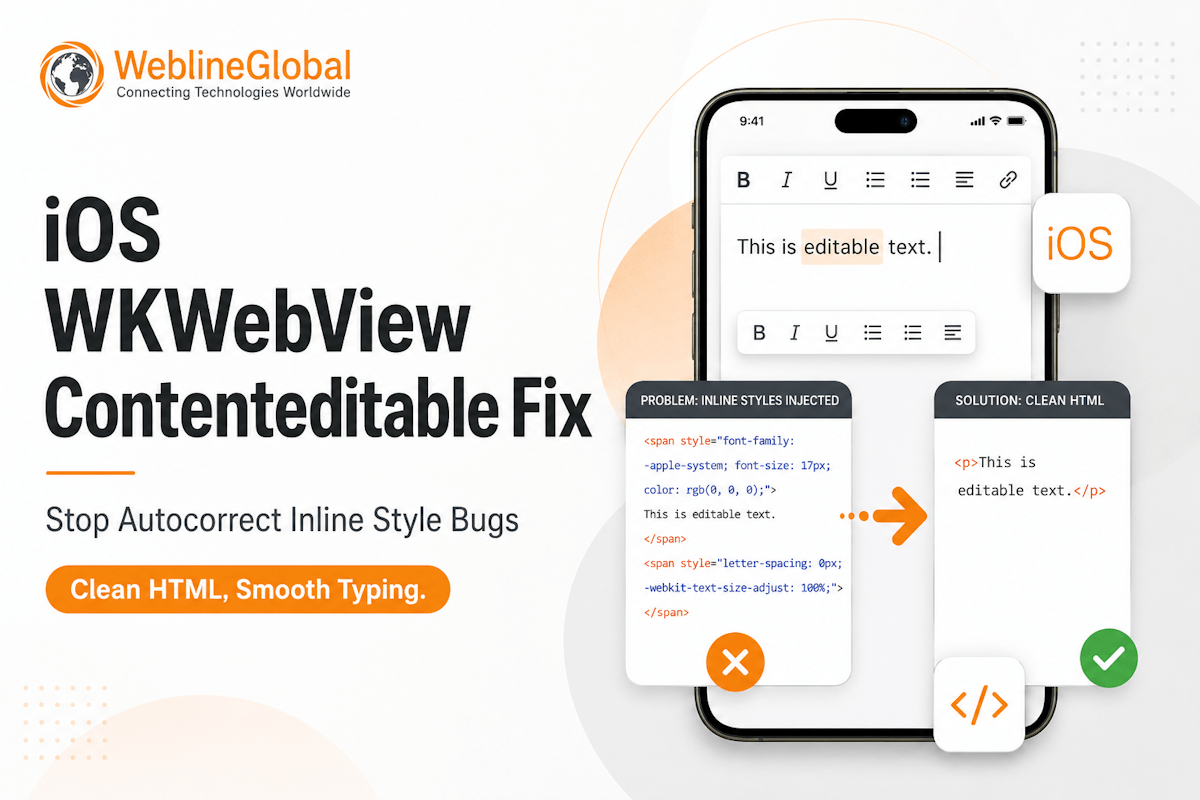

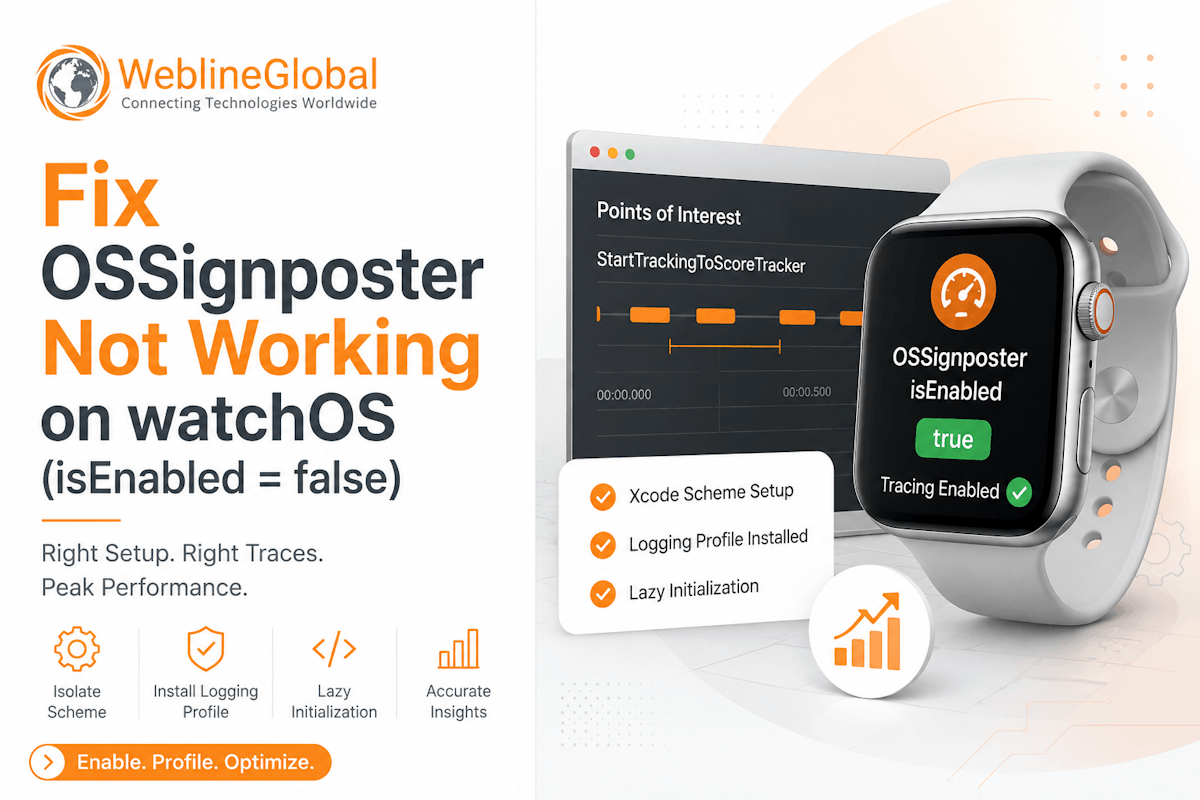
Success Stories That Inspire
See how our team takes complex business challenges and turns them into powerful, scalable digital solutions. From custom software and web applications to automation, integrations, and cloud-ready systems, each project reflects our commitment to innovation, performance, and long-term value.

California-based SMB Hired Dedicated Developers to Build a Photography SaaS Platform

Swedish Agency Built a Laravel-Based Staffing System by Hiring a Dedicated Remote Team












